About Me 🙈¶
- Software Engineer at Salesforce 👷
- Big passion for python, data and performance optimisations 🐍🤖
What's Pandas?🐼¶
- Library for data manipulation
- Dataset on Memory
- Widely used
Performance?! Why ?🤨¶
- Fast is better than slow 🐇
- Memory efficiency is good 💾
- Saving money is awesome 💸
- Hardware will only take you so far 💻

When ⏰¶
- Program doesn't meet requirements 🚔
- Program execution affects development pace 👷

Dataset 📉¶
In [9]:
df = load_dataset()
df.head()
Out[9]:
How 👀¶
Use What You Need 🧑¶
- Keep needed columns only
- Keep needed rows only

Dont Reinvent the Wheel 🎡¶
- Vast ecosystem
- Use existing solutions
- Less bugs
- Highly optimized
![]()
Avoid Loops ♾¶
Bad Option 😈¶
In [1]:
def iterrows_original_meal_price(df):
for i, row in df.iterrows():
df.loc[i]["original_meal_price"] = row["meal_price_with_tip"] - row["meal_tip"]
return df
In [5]:
%%timeit -r 1 -n 1
iterrows_original_meal_price(df)
Better Option 🤵¶
In [4]:
def apply_original_meal_price(df):
df["original_meal_price"] = df.apply(lambda x: x['meal_price_with_tip'] - x['meal_tip'], axis=1)
return df
In [5]:
%%timeit
apply_original_meal_price(df)
100x Improvement In Execution Time ⌛¶
Iterrow is evil 😈¶
Best Option 👼¶
In [65]:
def vectorized_original_meal_price(df):
df["original_meal_price"] = df["meal_price_with_tip"] - df["meal_tip"]
return df
In [66]:
%%timeit
vectorized_original_meal_price(df)
Another 8000x Improvement In Execution Time ⌛¶
Use Vectorized Operations 😇¶
Picking the Right Type 🌈¶
Motivation 🏆¶
In [67]:
ones = np.ones(shape=5000)
ones
Out[67]:
In [84]:
types = ['object', 'complex128', 'float64', 'int64', 'int32', 'int16', 'int8', 'bool']
df = pd.DataFrame(dict([(t, ones.astype(t)) for t in types]))
df.memory_usage(index=False, deep=True)
Out[84]:
Where We Stand 🌈¶
Dataframe Size 🏋️¶
In [70]:
df.memory_usage(deep=True).sum()
Out[70]:
Columns Sizes 🏋️¶
In [71]:
df.memory_usage(deep=True)
Out[71]:
Supported Types 🌈¶
- int64
- float64
- bool
- objects
- datetime64
- timedelta
Optimizing Types 🌈¶
- Loading dataframes with specific types
- Use to_numeric/to_datetime/to_timedelta functions with downcast parameter
In [11]:
df = df.astype({'order_id': 'category',
'date': 'category',
'date_of_meal': 'category',
'participants': 'category',
'meal_price': 'int16',
'type_of_meal': 'category',
'heroes_adjustment': 'bool',
'meal_tip': 'float32'})
Optimized Types 🌈¶
Dataframe Size 🏋️¶
In [75]:
df.memory_usage(deep=True).sum()
Out[75]:
Columns Sizes 🏋️¶
In [76]:
df.memory_usage(deep=True)
Out[76]:
12x Improvement In Memory ⌛¶
Custom Types 🦸🏼🦸♀️¶
- Open Sourced Types like cyberpandas and geopandas

Pandas Usage 🐼¶
Chunks 🍰¶
- Splitting large data to smaller parts
- Work with large datasets
In [53]:
def proccess_file(huge_file_path, chunksize = 10 ** 6):
for chunk in pd.read_csv(path, chunksize=chunksize):
process(chunk)
Mean/Sum/Mode/Min/etc optimization 🧮¶
- Types matter
In [32]:
%%timeit
df["meal_price_with_tip"].astype(object).mean()
In [33]:
%%timeit
df["meal_price_with_tip"].astype(float).mean()
20x Performance Improvement⌛¶
DataFrame Serialization 🏋¶
- Various file formats
- Loading time
- Saving time
- Disk space
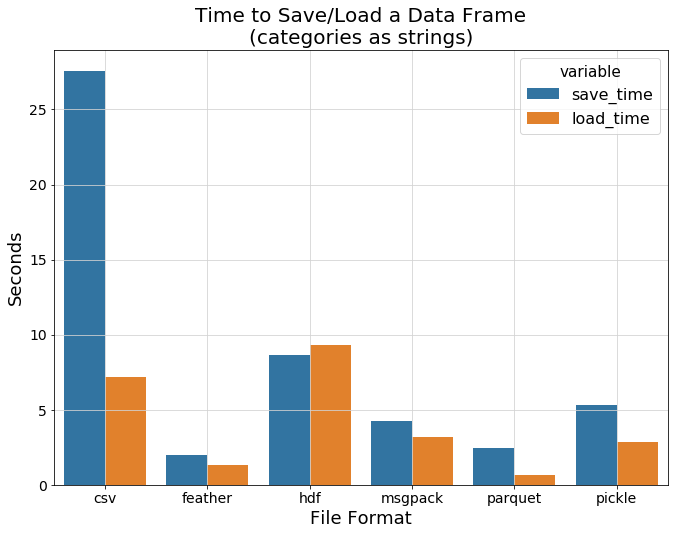
Query/Eval 🧬¶
- Use numexpr if installed
- Improve Execution Time 👍
- Improve Memory 👍
- Not all Operations are supported 👎
Example¶
In [28]:
%%timeit
df[df.type_of_meal=="Breakfast"]
In [29]:
%%timeit
df.query("type_of_meal=='Breakfast'")
% 20 Performance Improvement⌛¶
Use on big datasets 🧞¶
Concat vs Append ➕¶
- Every append creates a new dataframe object
- Multiple appends are inefficient
- Use concat
Sorting Optimization 📟¶
- Vanilla python
- Pandas
- Numpy
- Pytorch/Tensorflow

GroupBy Optimizations 👩👩👧¶
- Filter early
- Custom functions are slow
- Extract logic for custom functions when possible
Merge Optimization 🔍¶
- Filter/Aggregate early
- Semi join
Compiled Code ?! Why 🤯¶
- Python dynamic nature
- No compilation optimization
- Pure Python can be slow
In [17]:
def foo(N):
accumulator = 0
for i in range(N):
accumulator = accumulator + i
return accumulator
In [18]:
%%timeit
df.meal_price_with_tip.map(foo)
Cython and Numba for the rescue 👨🚒¶
Cython 🤯¶
- Up to 50x speedup from pure python 👍
- Learning Curve 👎
- Separated Compilation Step 👎 👍
Example¶
In [20]:
%%cython
def cython_foo(long N):
cdef long accumulator
accumulator = 0
cdef long i
for i in range(N):
accumulator += i
return accumulator
In [21]:
%%timeit
df.meal_price_with_tip.map(cython_foo)
49x Performance Improvement⌛¶
Numba 🤯¶
- Up to 200x speedup from pure python 👍
- Easy 👍
- Highly Configurable 👍
- Debugging 👎 👍
- Mostly Numeric 👎
Example¶
In [22]:
@jit(nopython=True)
def numba_foo(N):
accumulator = 0
for i in range(N):
accumulator = accumulator + i
return accumulator
In [23]:
%%timeit
df.meal_price_with_tip.map(numba_foo)
43x Performance Improvement⌛¶
1️⃣ Vectorized methods¶
2️⃣ Numba¶
3️⃣ Cython¶
General Python Optimizations 🐍¶
Caching 🏎¶
- Avoid unnecessary work/computation.
- Faster code
Intermediate Variables👩👩👧👧¶
- Intermediate calculations
- Memory foot print of both objects
- Smarter variables allocation
Example¶
In [37]:
def load_data():
return np.ones((2 ** 30), dtype=np.uint8)
In [50]:
%%memit
def proccess():
data = load_data()
return another_foo(foo(data))
proccess()
In [51]:
%%memit
def proccess():
data = load_data()
data = foo(data)
data = another_foo(data)
return data
proccess()
Concurrency And Parallelism 🎸🎺🎻🎷¶
- pandas methods use single process
- CPU bound can benefit parallelism
- IO bound is very bad without parallesim/concurrency
High Performance Python Book 📖¶

Pandas Alternatives 🐨🐻¶
- Libraries that provide dataframe apis
- No free lunch 🥢
How 👀¶
- Use What You Need 💾⌛
- Dont Reinvent the Wheel ⌛💾
- Avoid Loops ⌛
- Picking the Right Types 💾⌛
- Pandas Usage ⌛💾
- Compiled Code ⌛
- General Python Optimizations ⌛💾
- Pandas Alternatives ⌛💾
Additional Resources 📚¶
- Vectorization Mindset 📖
- Numpy/Pandas/Scipy vectorizations methods 📖
- Serialization Time 📖
- Chunks 📖
- Sorting📖
- Caching 📖
- Numba Workshop 🛠
- Cython Workshop🛠
- Numba VS C++ ⚖
- Cython VS C ⚖
- Intermediate Variables 📖
- High Performance Python Book 📖
- Pandas Alternatives 📖
